BIDL案例#
分类案例#
DVS数据处理#
动态视觉传感器(Dynamic vision sensor,DVS)是一种基于神经形态工程,模拟人类视网膜感知机制进行信息采集工作的硅视网膜(Silicon Retina)器件。DVS与传统的基于帧的传感器有着本质的区别。类似于人类视网膜收到光线刺激后向大脑发送脉冲,DVS以像素粒度异步、独立的接收光强信号,并将视觉信号编码为连续的时空事件流。神经拟态视觉传感器没有“帧”的概念。当现实场景中发生变化时,神经拟态视觉传感器会产生一些像素级的输出(即事件),一个事件具体包括(t, x, y, p),这里的x,y为事件在2D空间的像素坐标,t为事件的时间戳,p为事件的极性。事件的极性代表场景的亮度变化:上升(positive)或下降(negative)。
DVS Gesture#
网络模型
DVS Gesture数据在训练和推理的过程中均对时间窗口T进行循环操作,每个循环所执行的模型结构如下图所示,其中的输入为单拍,shape为[b,2,40,40]。最后的模型输出是所有60拍的output求和再除以60。
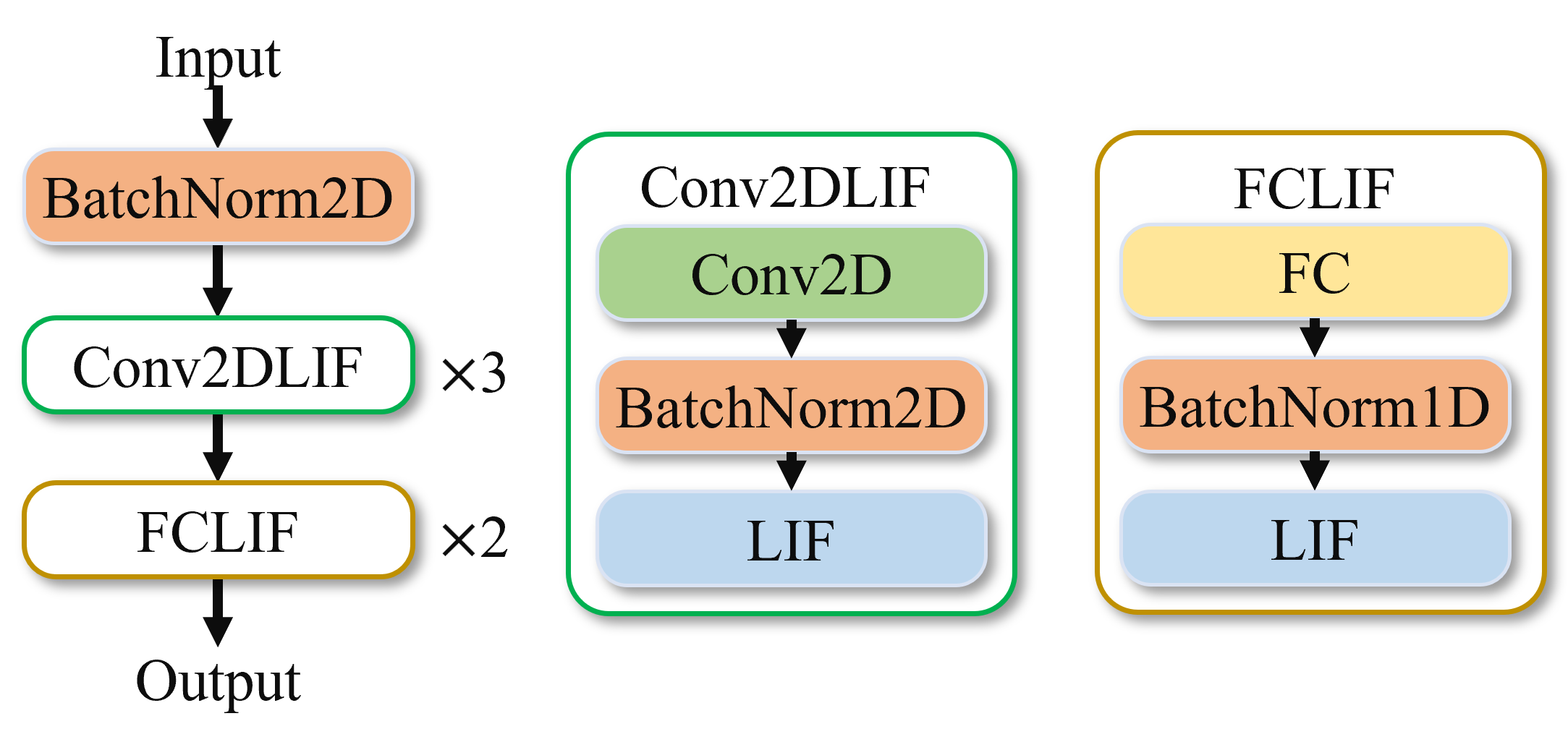
图 DVS-gesture网络模型#
该模型结构包含三个Conv2dLif模块以及2个FcLif模块,最后一个Fclif模块中Fc层的output_channel为DVS Gesture模型的类别数11。
训练与性能
随机选取数据集中的1176个样本做训练,288个样本做验证。我们使用学习速率为1e-2,权重衰减为1e-4的Adam优化器对这个网络进行训练,并且在训练过程中使用learning rate微调策略。神经元参数采用全共享模式,训练100个epoch,在验证集上达到了94.09%的top-1分类精度。
MNIST-DVS#
网络模型
MNIST-DVS网络模型包含3个Conv2dLif块,每个样本对时间拍进行循环,每次取单拍的样本送到这3个Conv2dLif块进行特征提取。之后会有一个SumLayer层,在该层对时间维度进行信息汇总,即将所有时间拍的特征图按元素相加并除以T,得到平均信息。模型的最后有FcBlock块,包含三层全连接,用于分类,最后一层Fc的out_channel为分类类别数10。
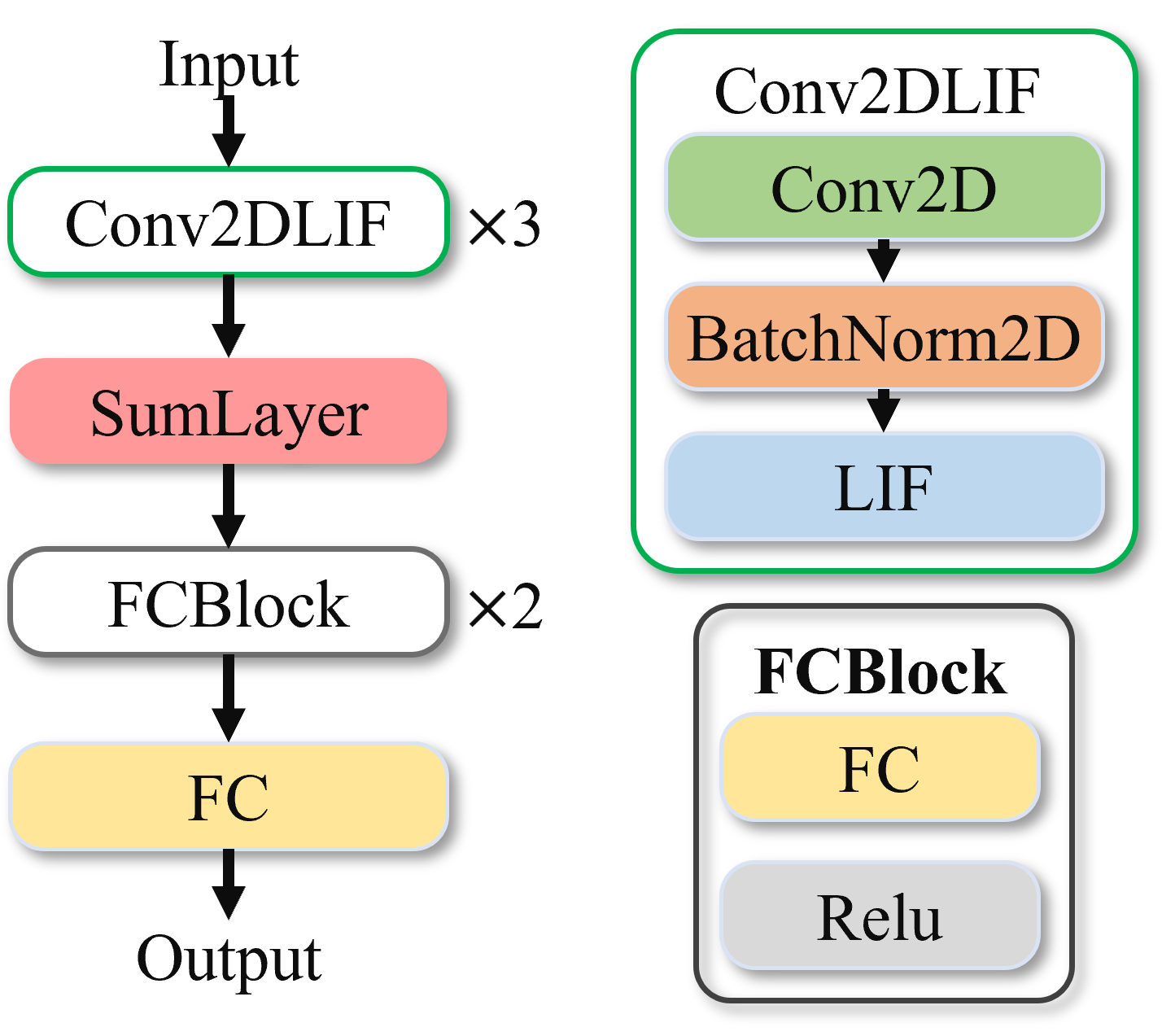
图 MNIST-DVS网络模型#
训练与性能
我们使用学习速率为1e-1,权重衰减为1e-4的带momentum的SGD优化器对训练集进行训练,momentum值设置为0.9,并且在训练过程中使用learning rate微调策略。神经元参数采用全共享模式,训练20个epoch,在验证集上达到了99.54%的top-1分类精度。
CIFAR10-DVS#
模型介绍
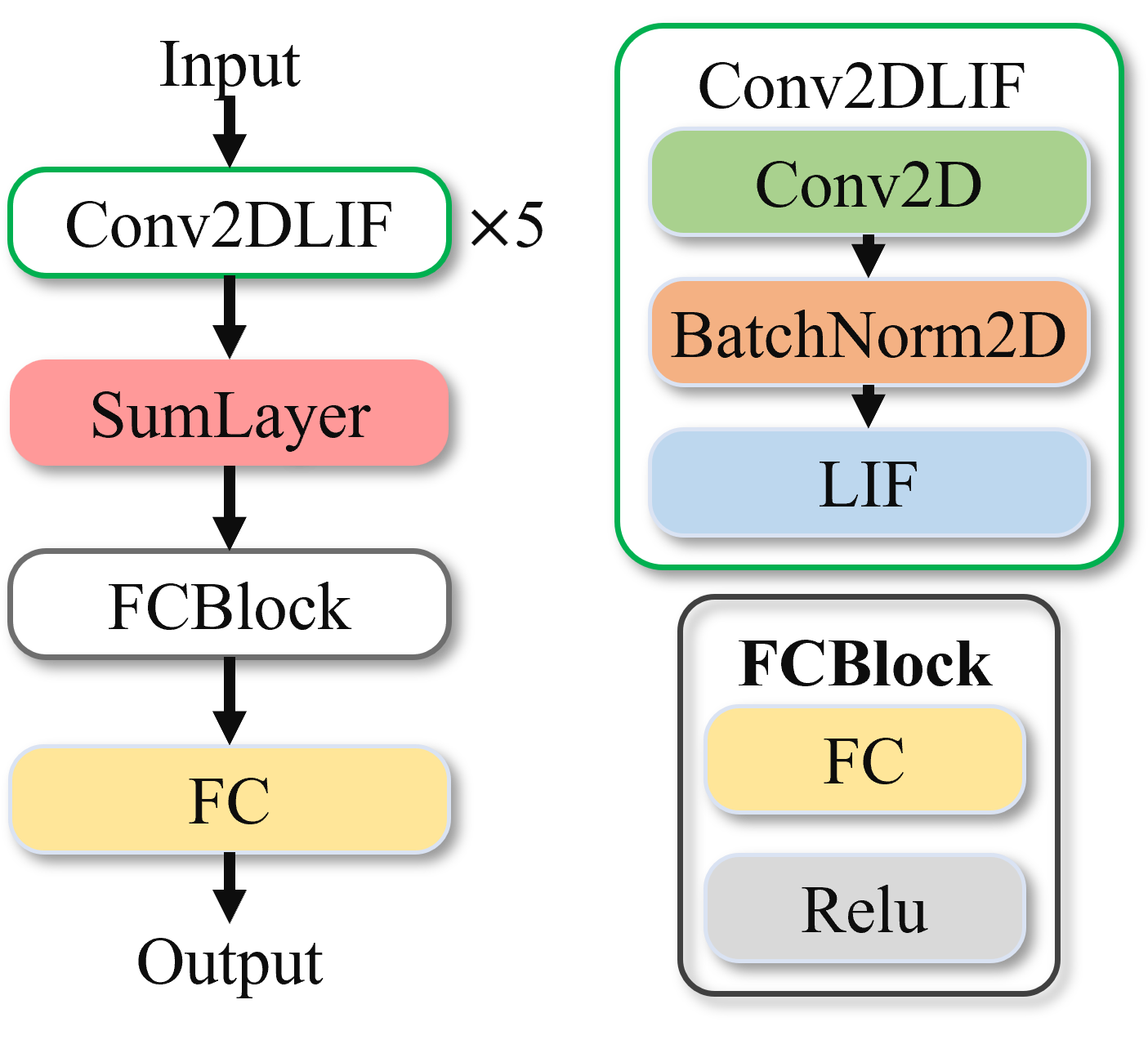
图 CIFAR10-DVS网络模型#
对比与MNIST-DVS,特征提取部分Conv2dLIf由三个增加至5个,而时间聚合层SumLayer后的FcBlock只包含2层Fc。
训练与性能
我们使用学习速率为1e-2,权重衰减为1e-4的Adam优化器对这个网络进行训练,并且在训练过程中使用learning rate微调策略。神经元参数采用全共享模式,训练100个epoch,在验证集上达到了68.23%的top-1分类精度。
短视频处理#
RGB-gesture#
训练与性能
RGB gesture数据的模型结构跟DVS gesture是一致的。我们使用学习速率为1e-3,权重衰减为1e-4的Adam优化器对这个网络进行训练,并且使用DVS gesture上训练的模型文件做为预训练的模型,训练50个epoch,在验证集上达到了97.05%的top-1分类精度。
Jester#
网络模型
训练Jester数据集的模型采用类resnet18的结构,具体如下图所示。
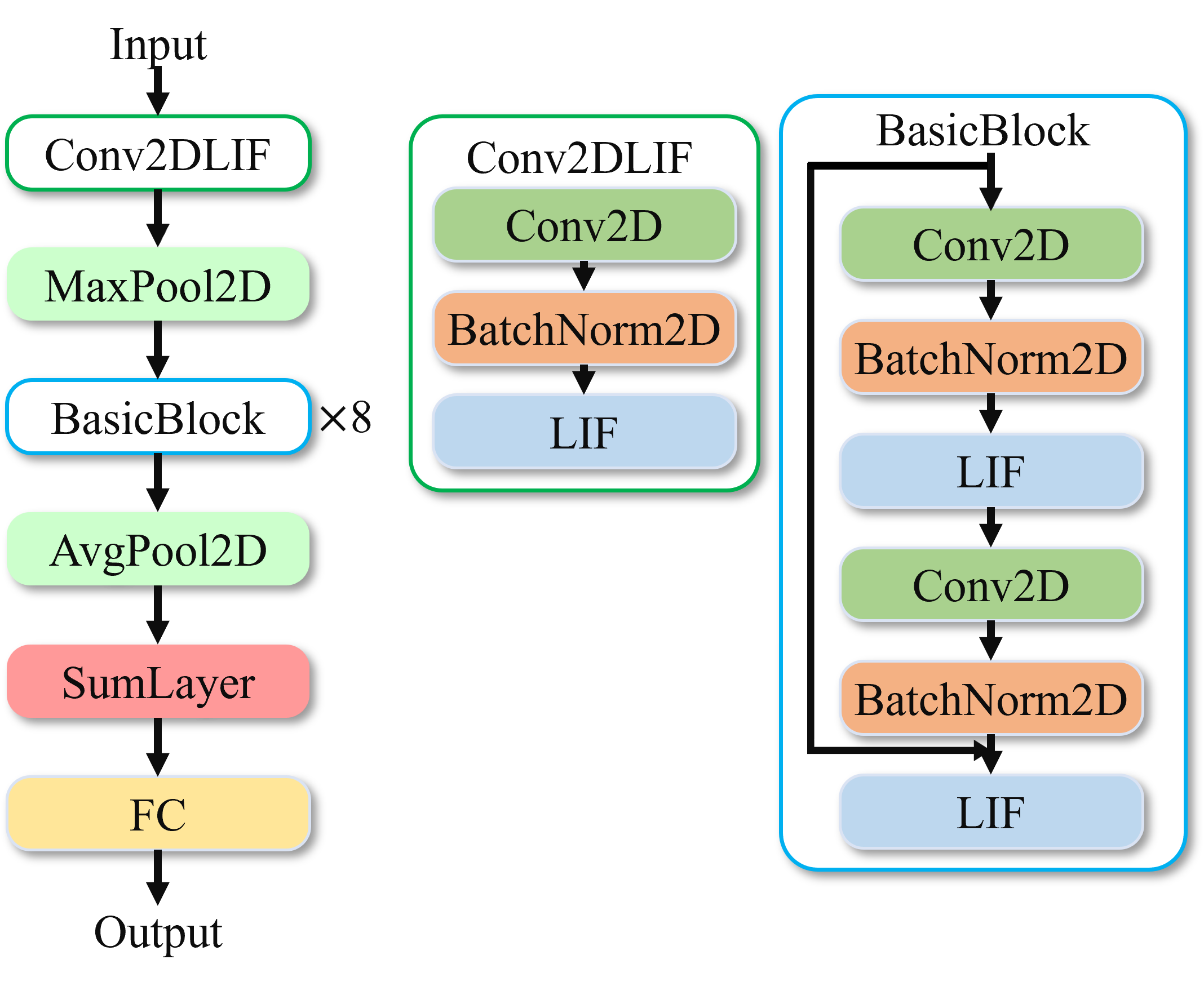
图 训练Jester数据集的模型#
同其它模型类似,SumLayer之前的均是单个时间步的操作,在SumLayer层,将所有时间步的结果进行求和再除以时间步16,进行时间维度的汇聚,最后再通过Fc层进行分类输出。
训练与性能
对训练集进行训练,优化器采用学习速率为1e-1,权重衰减为1e-4的带momentum的SGD优化器,momentum值设置为0.9,在训练过程中使用余弦退火的learning rate微调策略。训练200个epoch,在验证集上达到了93.87的top-1分类精度。
文本处理#
IMDB#
网络模型
IMDB模型同样是对时间拍进行循环操作,每次读入单时间拍的信息送入模型,模型首先通过Embedding层进行降维处理,之后通过FcLif层再进行升维操作,最后通过Fc层进行分类输出。该模型没有时间聚合层,只取最后一拍的结果做为输出。
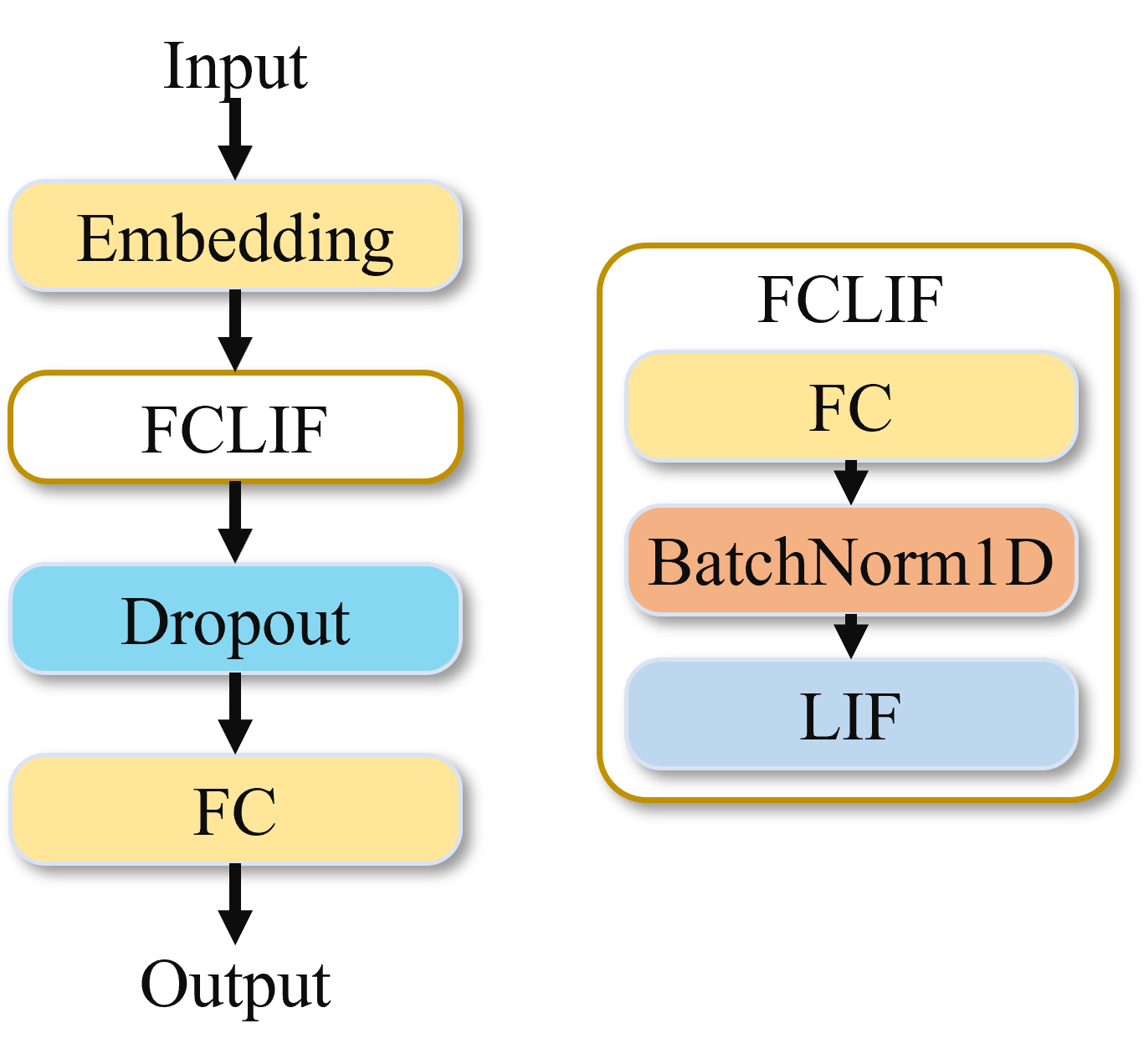
图 IMDB网络模型#
训练与性能
训练中采用的优化器是学习速率为1e-3,权重衰减为1e-4的Adam优化器,训练过程中根据epoch对学习速率进行微调。共训练50个epoch,在验证集上达到了82.8%的分类精度。
医学影像处理#
LUNA16Cls#
网络模型
Luna16Cls分类任务网络模型包含3个Conv2dLif块,每个样本对时间拍进行循环,每次取单拍的样本送到这3个Conv2dLif块进行特征提取。之后会有一个SumLayer层,在该层对时间维度进行信息汇总,即将所有时间拍的特征图按元素相加并除以T,得到平均信息。模型的最后有FcBlock块,包含三层全连接,用于分类,最后一层Fc的out_channel为分类类别数2。
图 Luna16Cls网络模型#
训练与性能
我们使用学习率0.05,权重衰减为1e-4,momentum为0.9的SGD优化器,对训练集进行训练,并在训练过程中使用学习率微调策略。神经元参数采用全共享模式,训练20个epoch,在验证集上达到了90.50%的top-1分类精度。在GPU上进行推理,速度为72.3fps。
大规模事件信息分类#
ESImagenet#
网络模型
网络的骨干网为resnetlif-18,同Jester数据集一样,只是LIF神经元的模式为 analog ,不同于Jester的 spike 模式。
训练与性能
我们使用学习率0.03,权重衰减为1e-4,momentum为0.9的SGD优化器,对训练集进行训练,并在训练过程中使用学习率微调策略。神经元参数采用全共享模式,训练25个epoch,在验证集上达到了44.16%的top-1分类精度。在GPU上进行推理,速度为121.6fps。
大规模图像分类#
Spike-driven Transformer V2#
介绍
Spikerformerv2(Spike driven transformer V2)是一种基于Transformer的通用SNN架构,称为“Meta - SpikeFormer”,旨在为神经形态计算提供一种高能效、高性能且通用的解决方案,可作为视觉骨干网络结构,在视觉任务方面表现出色。其特点包括:(1)低功耗,支持网络中仅存在稀疏加法的脉冲驱动范式;(2)通用性,处理各种视觉任务;(3)高性能,相比基于CNN的SNNs显示出压倒性的性能优势;(4)元架构,为未来下一代基于Transformer的神经形态芯片设计提供灵感。其采用Meta-SpikeFormer 架构, 借鉴通用视觉 Transformer 架构,将 Spike-driven Transformer 中的四个卷积编码层扩展为四个基于 Conv 的 SNN 块,并在最后两个阶段采用金字塔结构的 Transformer-based SNN 块。具体模型介绍请参考原论文[1].
Figure: Spike driven transformer V2 网络结构图#
性能
该网络取得了较为优秀的精度结果。在图像分类(ImageNet - 1K 数据集),Meta-SpikeFormer 取得了显著成果。例如,当参数为 55M 时,通过采用蒸馏策略,准确率可达 80.0%。在不同模型规模下,与其他方法相比,在准确率、参数和功耗方面展现出优势。此外,在基于事件的动作识别任务(HAR - DVS 数据集),对象检测(COCO 基准测试)、语义分割(ADE20K 和 VOC2012 数据集)等多种任务上都取得了很好的精度结果。
灵汐系统部署
本网络模型可通过单个KA200芯片部署,目前默认部署的模型为metaspikformer_8_512模型(预训练权重,55M参数版本,T=4(4个时间拍)。原先代码模型为Spikingjelly框架设计的,本案例对其进行了一定的修改并纳入了此软件栈。本代码只支持推理,不支持训练,如需训练,建议采用原代码框架进行。注:本案例只保证在灵汐类脑计算芯片复现了正确的推理结果,并不保证复现原论文的功耗和能效等指标。原代码链接:BICLab/Spike-Driven-Transformer-V2
参考文献
[1]. Yao, Man, et al. "Spike-driven transformer v2: Meta spiking neural network architecture inspiring the design of next-generation neuromorphic chips." arXiv preprint arXiv:2404.03663 (2024).
类脑跟踪(连续吸引子)案例#
Tiger1数据集目标跟踪#
数据及预处理
Tiger1数据集由一段分辨率为640×480的视频构成,该视频共354帧,每一帧均有人工标注的矩形框(x, y, w, h)作为待跟踪目标的groundtruth,其中x, y为矩形框的左上角坐标,w,h分别为矩形框的宽和高。视频中,有光照度变化,待跟踪目标存在被阻挡情况,存在目标发生形变情况,存在目标动作模糊情况,存在目标在平面内及平面外旋转的情况。
为节省图形内存,我们将每一帧彩色图像先转换为灰度图像,然后下采样至30×56分辨率。
网络模型
此任务中用到的网络模型是连续吸引子网络(CANN),是一种受神经科学启发的模型。如下图所示,x为二维平面上的坐标位置,\(V(x,\ t)\)为位置x和时间t的神经元的膜电位,
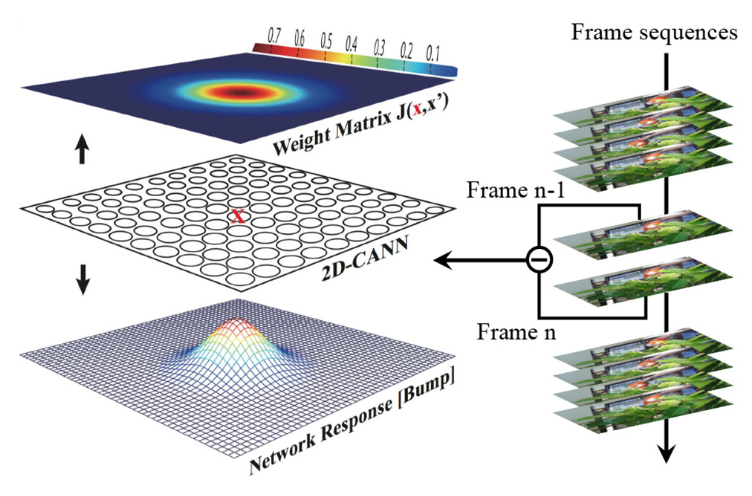
图 CANN原始动态模型示意图#
基于CANN的对象跟踪实例
r(x,t)为该神经元的发射率。有理由认为,\(r(x,\ t)\)随着\(V(x,\ t)\)的增加而增加,但在存在全局抑制的情况下达到饱和。满足这一特性的模型可表示为:
其中k是一个小的正超参数,控制全局抑制的强度。
在CANN模型中,\(V(x,\ t)\)是由外部刺激和来自其他神经元的递归输入以及其自身的松弛度决定的。用\(V_{ext}(x,t)\)表示在时间t对神经元x的外部刺激,则该模型可表示为:
其中\(\tau\)是一个时间常数,通常在1毫秒的量级,\(\beta\)决定了循环输入和外部刺激之间的比例。\(J\left( x,x^{'} \right)\)是位于\(x^{'}\)位置的神经元与位于\(x\)位置的神经元之间的相互作用(突触权重)。 \(J\left( x,x^{'} \right)\)计算如下:
其中\(J_{0}\)是一个常数,\(a\)表示高斯交互作用范围, \(|x - x^{'}|\)表示神经元\(x\)和\(x^{'}\)\(\frac{J_{0}}{2\pi a^{2}}\)是最大的交互范围。上述公式对具有平移不变性的突触模式(凸起形状)编码,产生类似的由神经元的高放电率表示的响应凸起模式。响应凸起可以预示对象的位置。此外,神经元距离是圆形的,这意味着最顶部和底部的神经元以及最左侧和最右侧的神经元作为相邻神经元连接。这种对称性保证了边界处的凸起稳定性。
如 图 CANN原始动态模型示意图 所示,来自视频的每两个相邻帧的差分信号被注入网络作为外部刺激 \(V_{ext}(x,t)\),每个神经元接收2D差分帧中相应像素的强度。CANN能够平滑地跟踪对象,因为连续的神经动力学导致响应凸起的移动轨迹是平滑的。轨迹有如下特性:
在没有外部刺激的情况下,网络仍然可以通过循环注入保持固定的响应凸起;
在存在物体的情况下,尤其是连续移动的物体,网络可以根据移动目标平滑地改变其响应凸起。 上述视频展示了一个基于CANN的对象跟踪实例,红色边界框是物体位置的金标准,响应凹凸表示的黄色边界框反映了预测的位置。
由于远程连接通常对神经元膜电位和发射率的影响很小,同时为了更方便在数字电路实现,公式(2)可在没太多精度损失的情况下表示为:
其中\(x^{'} \in CF(x,\ R)\)表示每个神经元x只与以x为中心的R×R矩形区域内的邻近神经元有局部联系。
由于数字电路不能直接支持公式(1)和公式(2)中的连续微分动力学,可采用迭代状态更新方法,将连续动力学离散为等效的差分方程。通过设置τ=1和∂t=1,CANN的连续状态更新可以被修改为迭代版本的。
因此,整个计算数据流变成了\(\{ r(x,\ t)\ \&\ Vext(x,\ t)\}\ \Rightarrow \ V(x,\ t\ + \ 1)\ \Rightarrow \ r(x,\ t\ + \ 1)\ \Rightarrow \ ...\)。通过这一离散化过程,平面连续吸引子模型可在数字电路上通过迭代实现。
为了更好地理解将CANN拓扑结构映射到多核NN架构上的过程,我们将差分方程公式(3)的每个迭代分解为以下5个步骤:
循环输入:
膜电位:
\[V(x,t + 1) = V_{1}(x,t + 1) + V_{ext}(x,t)\]电位平方:
\[V^{2}(x,t + 1) = V(x,t + 1) \cdot V(x,t + 1)\]抑制因子:
\[s_{inh}(t + 1) = \frac{1}{k\sum_{x^{'}}^{}{V^{2}\left( x^{'},t + 1 \right)}}\]发放率:
\[r(x,t + 1) = V^{2}(x,t + 1) \cdot s_{inh}(t + 1)\]
DVS高速目标检测案例#
ST-YOLO人车目标检测#
数据及预处理#
Gen1数据集是使用安装在汽车仪表板上的PROPHESEE GEN1传感器记录的,该传感器的分辨率为 \(304 \times 240\)像素。标签是利用 ATIS摄像机的灰度估计功能生成特定频率的标准灰度图像,进而通过手动标注获得。该数据集包含39个小时的开放道路和各种驾驶场景,包括城市、高速公路、郊区和乡村场景。手动标注的边界框包含两个类别:行人和汽车。
为了便于深度学习方法的训练,我们将连续拍摄的数据剪切成60秒的片段。这样,共获得2359个样本:训练数据为1460个,测试数据为470个,验证数据为429个。每个样本都以二进制.dat格式提供,其中事件编码使用4个字节表示时间戳,4个字节表示位置和极性。更确切地说,x位置使用14位,y位置使用14位,极性使用1位。
边界框注释以numpy格式提供。每个numpy数组都包含以下字段:
-ts,方框的时间戳(以微秒为单位);
-x,左上角的横座标(以像素为单位)
-y,左上角的纵座标(以像素为单位);
-w,方框的宽度(以像素为单位);
-h,方框的高度(以像素为单位);
-class id,对象的类别:
汽车为0;
行人为1。
预处理步骤首先是创建一个四维张量E:
第一个维度由两个部分组成,代表极性;
第二个维度有T个分量,与时间的T个离散化步长相关;
第三个维度和第四个维度分别代表事件摄像机的高度和宽度。
按以下方法处理时间段[\(t_{a}\), \(t_{b}\)]内的事件集E:
换句话说,我们创建了T个双通道帧,其中每个像素包含T个时间帧中一个帧内正负事件的数量。最后,我们对极性和时间维度进行了扁平化处理,以获取形状为(2T、H、W)的三维张量,从而直接与二维卷积相兼容。
网络模型#
ST-YOLO网络可基于时间空间动力学,进行事件流数据目标检测。事件流信息按顺序输入网络后,首先被处理成代表空间和时间事件的张量。每一个时间步都会有一个新的事件张量输入网络,此外,特定的Lif层还会接受之前时间步的状态。每次经过骨干网后,Lif层的输出都会被用作检测框架的输入。具体结构如下图所示。
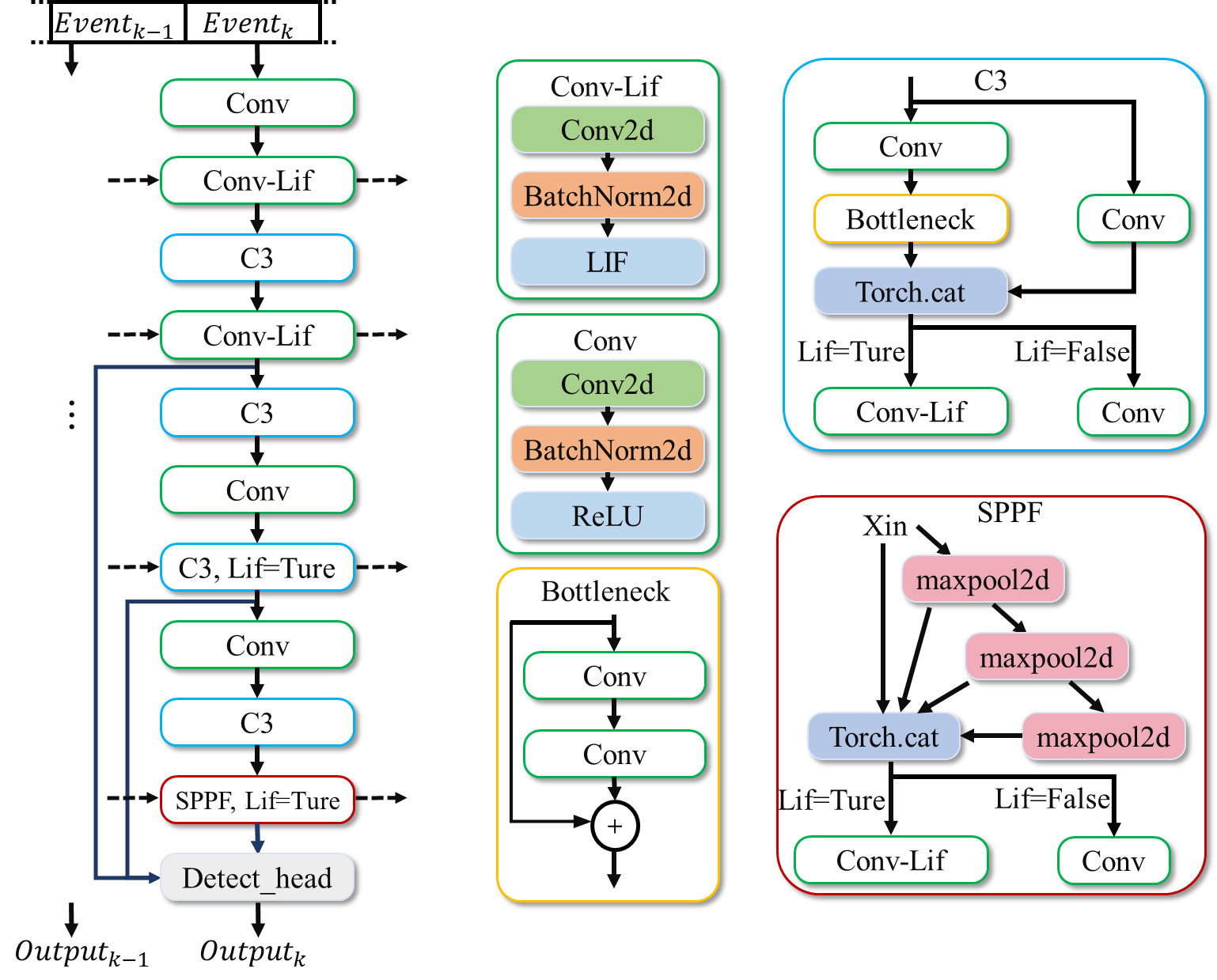
图 ST-YOLO网络架构图#
该网络包含backbone,Detect_head两个部分。其中,backbone部分基于yolov5的backbone进行修改,主要是使用了Lif层替代ReLU层,并利用Lif层的时空特性,处理时间维度的信息。Detect_head部分包含一个FPN网络和一个YoloXhead。
演示示例#
将GEN1数据集测试集中的数据输入上述网络,可输出事件流数据目标检测帧序列。以下视频为演示示例:
ST-YOLO人车目标检测演示示例
DVS高速转盘目标检测#
数据及预处理#
本数据集使用灵汐科技自有的高速移动目标数据采集装置进行数据采集,该装置示意图如下图所示。DVS事件流数据采集后,经过事件流成帧处理,标签生成,数据集整合等步骤后,形成完整的DVS高速转盘目标检测数据集。本数据集共三类目标,分别为{0: 'Cross', 1: 'Triangle', 2: 'Circle'}。
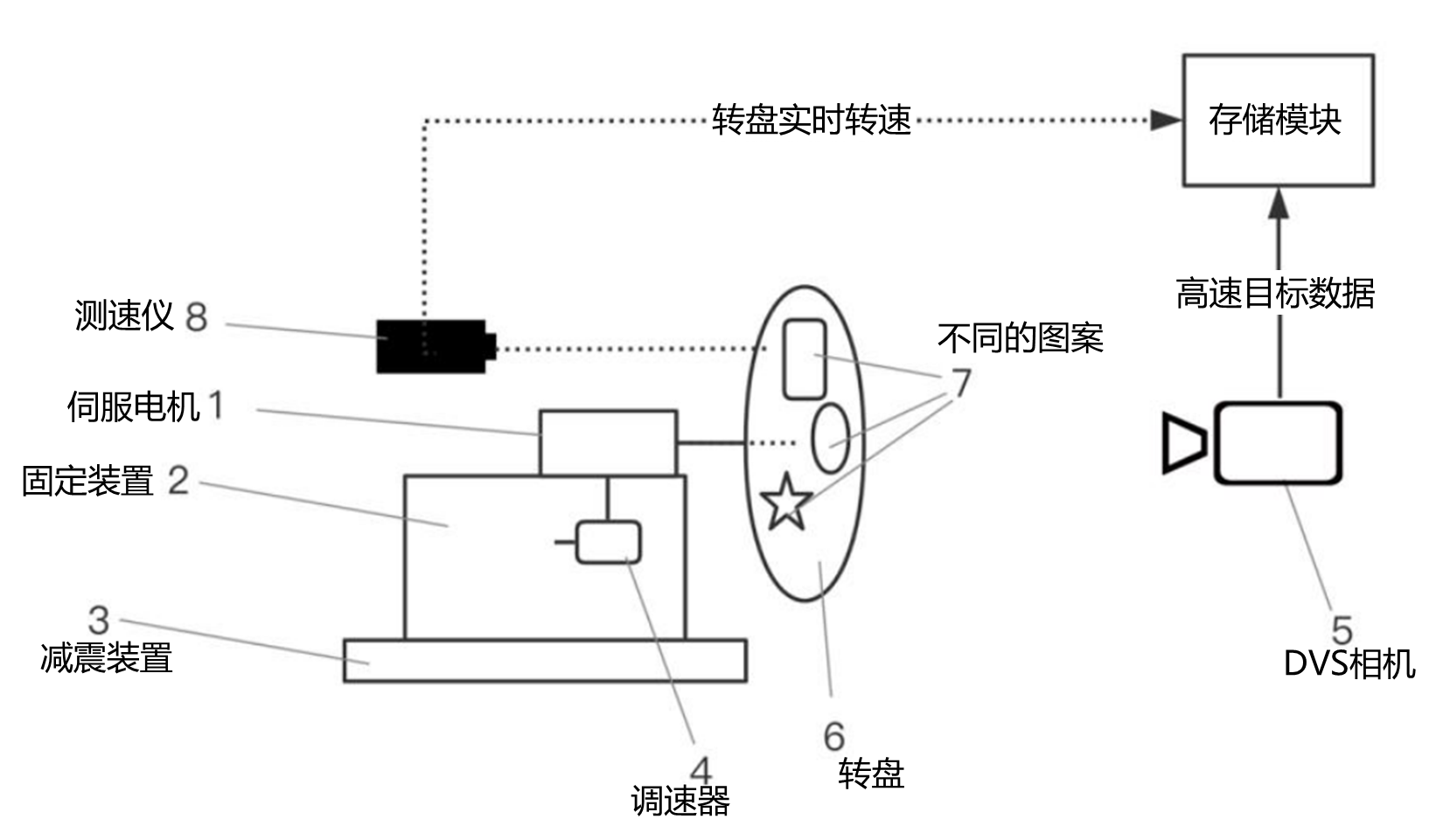
图 高速移动目标数据采集装置#
网络模型#
DVS高速转盘目标检测采用ST-YOLO网络,基于时间空间动力学,进行事件流数据目标检测。与 ST-YOLO人车目标检测 人车目标检测所不同的是,由于数据集标注格式差异,本任务中,网络head部分采用yolov5 head。
演示示例#
将测试集中的数据输入上述网络,可输出高速转盘事件流数据目标检测帧序列。以下视频为演示示例:
DVS高速转盘目标检测演示示例
位置识别案例#
位置识别机器人简介
此四足机器人包含有多个传感器:IMU惯性测量仪用于获取位置信息,RGB摄像头用于获取图像数据,时间摄像机用于获取事件数据;一颗神经形态芯片:用于处理多模态的数据。
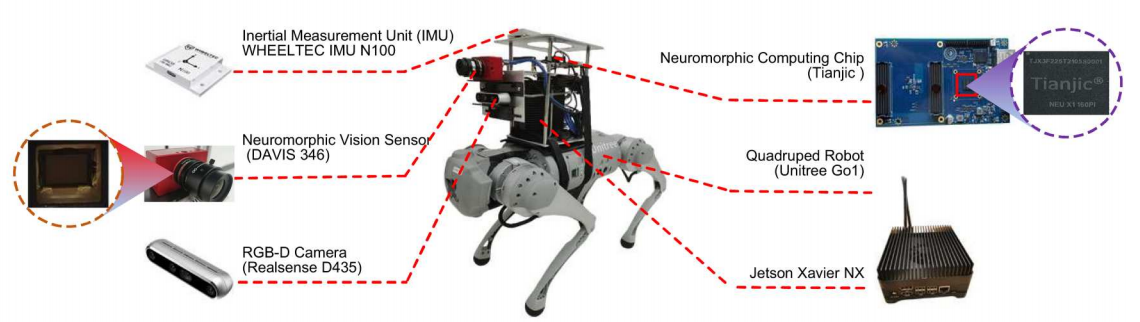
图 位置识别机器人#
网络模型
位置识别网络的架构见下图,该网络包含四个模块:卷积神经网络(可使用预训练的resnet50或mobilenet_v2)用于处理图像数据,SNN网络用于处理事件数据,连续吸引子网络(即CANN)用于处理GPS信息,这三个模块处理后的多模态数据输入到MLSM模块(即液体状态机)进行处理,最终得到位置信息。
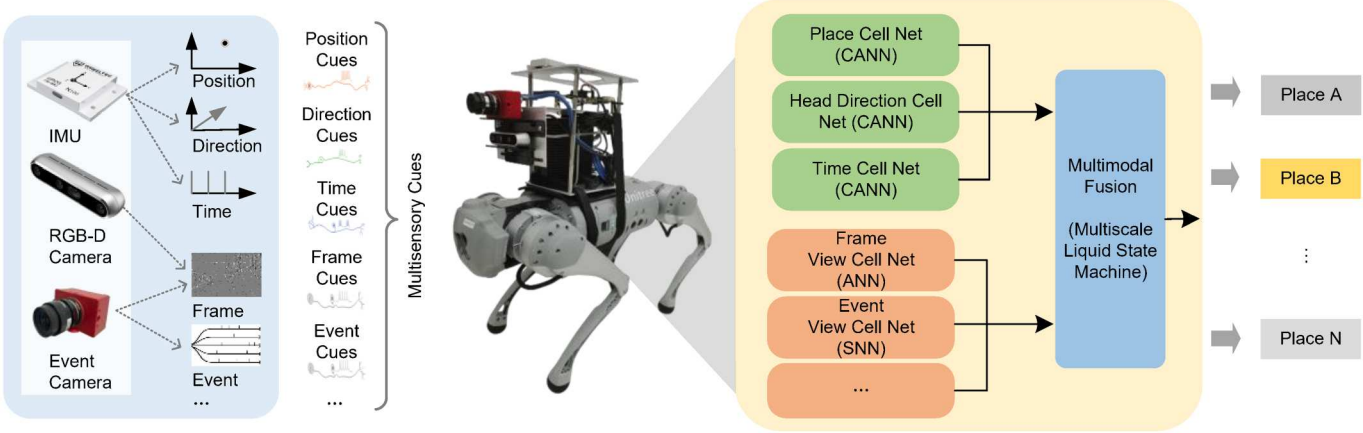
图 位置识别网络架构图#
弱小目标识别#
PCNN#
网络模型
基于PCNN(脉冲耦合神经网络)对输入图像进行处理,实现背景抑制和目标增强。用于红外运动弱小目标的检测任务。
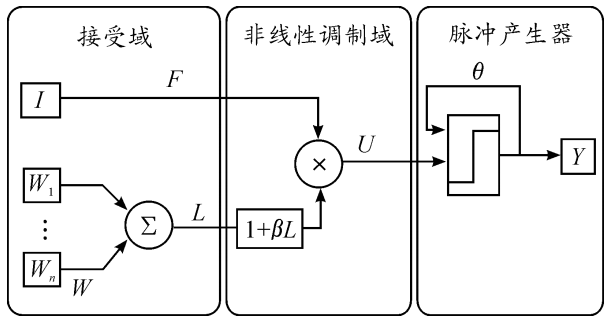
图 PCNN网络模型#
训练与性能
PCNN网络无需训练。下列视频为PCNN网络部署在APU上的检测效果展示:
PCNN网络部署在APU上的检测效果示例
pcnn_de#
脉冲耦合发放算法(Pulse-Coupled Neural Networks,PCNN)是一种基于神经生物学的启发而设计的算法,主要用于图像处理领域,特别是在图像分割、目标识别和纹理分析等方面。PCNN模拟了生物视觉系统中的神经元活动,特别是视网膜上的神经元如何通过同步发放脉冲来响应视觉刺激。本案例展示了基于一种改进地PCNN的可见光小目标(飞机)检测。该算法无需复杂训练,可用于小样本目标的检测。
本案例展示地PCNN网络由侧抑制滤波器和变阈值动态神经元两部分组成。第一部分利用侧抑制对图像滤波进行预处理来抑制复杂背景。第二部分通过可变阈值来产生脉冲信号实现目标与背景分割的目的。分离采用脉冲发放实现,发放的神经元代表目标前景,未发放代表背景。该过程持续N个迭代次数。迭代过程中,阈值动态变化,并通过卷积操作逐渐提升发放目标周边的像素的取值,从而将目标区域扩大,最终获得目标区域,并计算目标区域的位置及边界,得到检测输出。像素点对应的发放阈值的调节规律如下:阈值T每个像素不同,当输入图像在像素已被检测为前景像素时,T取较高值Tmax,当输入像素未达到阈值时,T减少一个定值,用于更容易地在后一轮次中发放。信号O在多轮迭代中将自身与X相加,从而收集所有已发放的神经元,得到前景目标。后处理进一步将O二值化,并计算目标框位置。整体流程如下图所示。
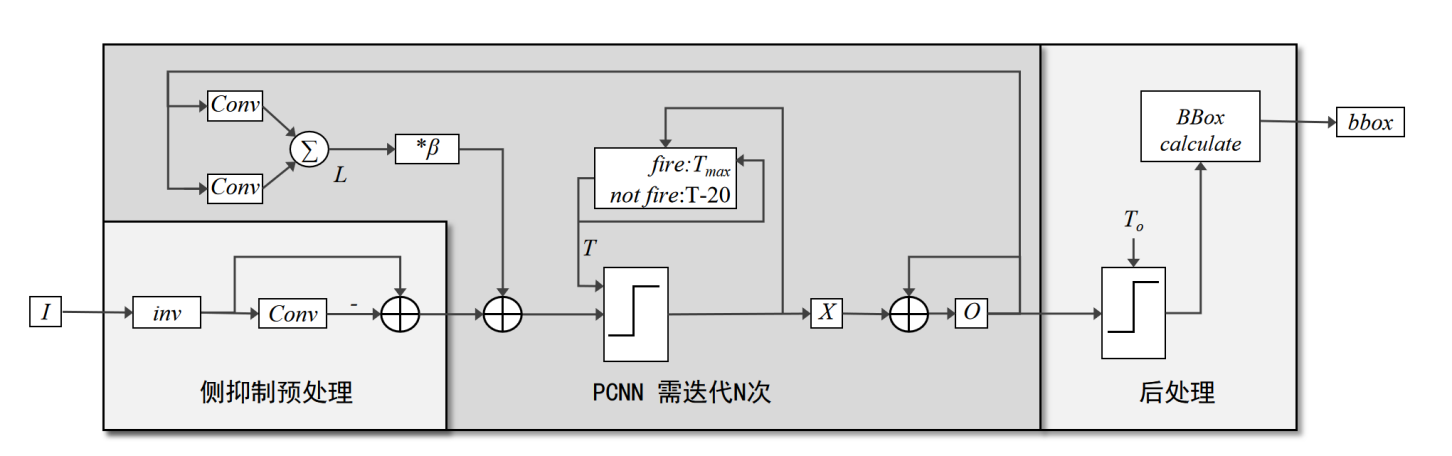
图 pcnn_de算法流程图#
检测的输入为一个视频,效果如下所示:
pcnn_de算法效果检测示例
频率/时间/群编码支持案例#
频率编码#
频率编码使用输入特征来确定脉冲的频率。神经元发放脉冲的频率包含了所有的信息。脉冲计数频率的度量可以仅通过计算时间区间内脉冲的个数来完成,也就是计算时间上的平均。神经元脉冲发放的频率可以理解为在一个特定的时间区间T内观察到的平均脉冲个数与时间T的比例。
时间编码#
时编码捕获神经元的精确放电时间信息;单个脉冲比依赖于发射频率的频率码具有更多的含义。任何脉冲序列都有对应其自身的时间发放模式,因此与刺激有关的信息有可能由脉冲的精确发放时间来表达。具体而言,时间编码认为神经元脉冲序列的时间结构在毫秒甚至更小尺度上携带了刺激信号,而不仅仅只是平均发放频率。
脉冲延迟编码是时间编码的一种,该编码方法将信息包含在一组相互关联脉冲的精确发放时间结构中。
群编码#
区别于通过单个神经元进行编码的方法,神经信息还可以通过多个神经元的集群活动进行编码。群编码是一种运用多个神经元的集群反应来编码刺激信号的方法。在群编码中,每个神经元对于给定的输入刺激具有特有脉冲响应分布,神经元群体的响应组合在一起表征整体的信息输入。
该案例采用高斯调谐曲线的方法进行群编码,将一个模拟量转化为不同神经元的一组脉冲时间。一个神经元以高斯函数的形式覆盖模拟量的一定范围,模拟量的某个值对应的高斯函数的高度决定了该神经元发放脉冲的时间。
数据集以及网络模型#
该案例对MNIST数据集进行编码,转化为多拍的脉冲数据作为模型输入。模型采用
DVS-MNIST数据集的序贯模型,包含 ConvLif x3、FC x3。
内循环支持案例#
模型说明#
CIFAR10-DVS内循环案例的配置文件为resnetlif50-it-b16x1-cifar10dvs.py,采用resnet50模型结构,与外循环模型结构保持一致。模型backbone名称为 ResNetLif ,在 bidlcls/models/backbones/residual/bidl_resnetlif.py 文件中定义。
与外循环不同的是,无论是否在APU上运行,模型均接受5维的数据输入[t,b,c,h,w],对于lif层,将时间拍展开进行计算,而对于卷积层等,将时间拍维度和batch维度合并,按照4维数据进行计算。
编译和部署#
在APU上编译时,模型结构中的lif层需采用 bidlcls/models/layers/lif_itin.py 文件中的Lif2dIt类。
使用网络汇总#
外循环模式的模型#
简单序贯
模型 |
说明 |
|---|---|
SeqClif3Fc3DmItout |
用于DVS-MNIST数据集的序贯模型,包含 ConvLif x3、FC x3; |
SeqClif5Fc2DmItout |
用于DVS-MNIST数据集的序贯模型,包含 ConvLif x5、FC x2; |
SeqClif3Flif2DgItout |
用于DVS-Gesture数据集的序贯模型,包含 ConvLif x3、FcLif x2; |
SeqClif7Fc1DgItout |
用于DVS-Gesture数据集的序贯模型,包含 ConvLif x7、FC x1; |
SeqClif5Fc2CdItout |
用于CIFAR10-DVS数据集的序贯模型,包含 ConvLif x5、FC x2; |
SeqClif7Fc1CdItout |
用于CIFAR10-DVS数据集的序贯模型,包含 ConvLif x7、FC x1; |
FastText |
用于IMDB数据集; |
SeqClif3Fc3LcItout |
用于Luna16Cls数据集的序贯模型,包含ConvLif x3、FC x3; |
ResNet系列
模型 |
说明 |
|---|---|
ResNetLifItout-10 |
不限定数据集,用Lif替换ReLU,包含四个阶段,每个 阶段1个残差块; |
ResNetLifItout-18 |
不限定数据集,用Lif替换ReLU,包含四个阶段,每个 阶段2个残差块; |
ResNetLifItout-50 |
不限定数据集,用Lif替换ReLU,包含四个阶段,每个 阶段残差块分别为3、4、6、3; |
内循环模式的模型#
简单序贯
模型 |
说明 |
|---|---|
SeqClif2Fc2Lc |
用于LUNA16数据集的序贯模型,包含ConvLif x2、FC x2; |
SeqClif3Fc2Rg |
用于RGB-Gesture数据集的序贯模型,包含ConvLif x3、FC x2; |
SeqClif3Fc3Dm |
用于DVS-MNIST数据集的序贯模型,包含ConvLif x3、FC x3; |
SeqClif3Flif2Dg |
用于DVS-Gesture数据集的序贯模型,包含ConvLif x3、FcLif x2; |
SeqClif4Flif2Dg |
用于DVS-Gesture数据集的序贯模型,包含ConvLif x4、FcLif x2; |
SeqClif5Fc2Cd |
用于CIFAR10-DVS数据集的序贯模型,包含ConvLif x5、FC x2; |
SeqCtlif5Fc2Cd |
用于CIFAR10-DVS数据集的序贯模型,包含Conv+Lif x5、FC x2; |
SeqClif5Fc2DmIt |
用于DVS-MNIST数据集的序贯模型,包含ConvLif x5、FC x2; |
SeqClif7Fc1DgIt |
用于DVS-Gesture数据集的序贯模型,包含ConvLif x7、FC x1; |
SeqClif5Fc2CdIt |
用于CIFAR10-DVS数据集的序贯模型,包含ConvLif x5、FC x2; |
SeqClif7Fc1CdIt |
用于CIFAR10-DVS数据集的序贯模型,包含ConvLif x7、FC x1; |
ResNet系列
模型 |
说明 |
|---|---|
ResNetLif-10 |
不限定数据集,用LIF替换ReLU的ResNet10,包括4个阶段、每个 阶段1个残差块; |
ResNetLif-18 |
不限定数据集,用LIF替换ReLU的ResNet18,包括4个阶段、每个 阶段2个残差块; |
简单双塔
模型 |
说明 |
|---|---|
DualFlifp1Fc1Bq |
用于bAbI-QA数据集的朴素双塔模型,包括{ FcLif x1, FcLif x1}、FC x1; |